Hand Image Classification – Part 3 – Prediction on my own images
Introduction
In Part 1 and Part 2, we developed algorithms to classify the number of fingers held up as well as the hand used in an image. In this article, we upload photos taken using a mobile phone, resize them, and apply the algorithms developed to see their performance in cases which do not resemble the hand images the algorithms were trained on in subtle ways.
I use a set of images taken via the camera on a mobile phone and see if they are correctly classified with the correct number of fingers as well as the correct hand. I took 6 photos of my hand using my phone in a similar fashion to those in the training set. I then added a strip of black along the bottom to match that of the training set. I then took additional photos with small differences to the training set, i.e. with a white background instead of black, including the wrist in the images etc…
This article assumes that the models from the previous parts were saved locally.
Imports
import Directory # for keeping a solid directory structure
import numpy as np
np.random.seed(101) # set random seed
# import PIL # for reading in the png files
from matplotlib import image # for displaying the image files
import matplotlib.pyplot as plt
import os
# import time # to time some operations
# from sklearn.linear_model import LogisticRegression
# from sklearn import metrics
import tensorflow as tf
from tensorflow import keras
#from tensorflow.keras import layers
# from tensorflow.keras.layers import Input,Dense,Activation,Dropout,Conv2D,Flatten,BatchNormalization
from tensorflow.keras.models import Model, load_model
# from tensorflow.keras.utils import to_categorical
# %matplotlib inline
Global Variables
# setting up the folder paths for where the images are located
dir_image_folder = os.path.join(Directory.dataPath,'my_fingers')
dir_image_folder2 = os.path.join(Directory.dataPath,'my_fingers_errors')
# the locations of the models
model_h5_save = os.path.join(Directory.outputPath,'finger_count_model.h5')
model_h5_rlmodel_save = os.path.join(Directory.outputPath,'finger_count_model_rl.h5')
Load Data
In this step we load the images from a directory. There are a few differences between this dataset and the ones the models were trained on:
- Each image in this dataset has 3 channels (RGB). We will need to collapse the channels into a single channel representing grayscale. One way to do this is to take the average value over the channels.
- The values in these images are from 0 to 255. We will need to scale these by dividing by 255.
- Each image in this dataaset is an array of dimensions 256 X 256. We will see below that the models expect an array of size 128 X 128. We can use a max pooling function shrink the images here into a size the model expects.
# get a list of all the images that are in the directories
dir_all_images = os.listdir(dir_image_folder)
# get the number of train/test examples
number_of_images = len(dir_all_images)
print('Number of images:',number_of_images)
Number of images: 7
Below we can see the colour images which we will need to turn into grayscale:
for img_name in dir_all_images:
data = image.imread(os.path.join(dir_image_folder,img_name))
plt.imshow(np.array(data))
plt.show()







# lists to store the images
ls_X = []
for img_name in dir_all_images:
data = image.imread(os.path.join(dir_image_folder,img_name))
ls_X.append(np.array(data))
ls_X = np.array(ls_X)
# convert to grayscale by averaging across rgb channel
ls_X = np.mean(ls_X,axis=3)
# scale by rgb values 255
ls_X = ls_X/255
print('Train images loaded:',len(ls_X))
Train images loaded: 7
ls_X.shape
(7, 256, 256)
Transform
While the above previous section did have some transformations, these were very simple. Here, we will need to apply a more complex transformation. This transformation will take a 256 X 256 array and shrink it to a 128 X 128 array while keeping important features intact.
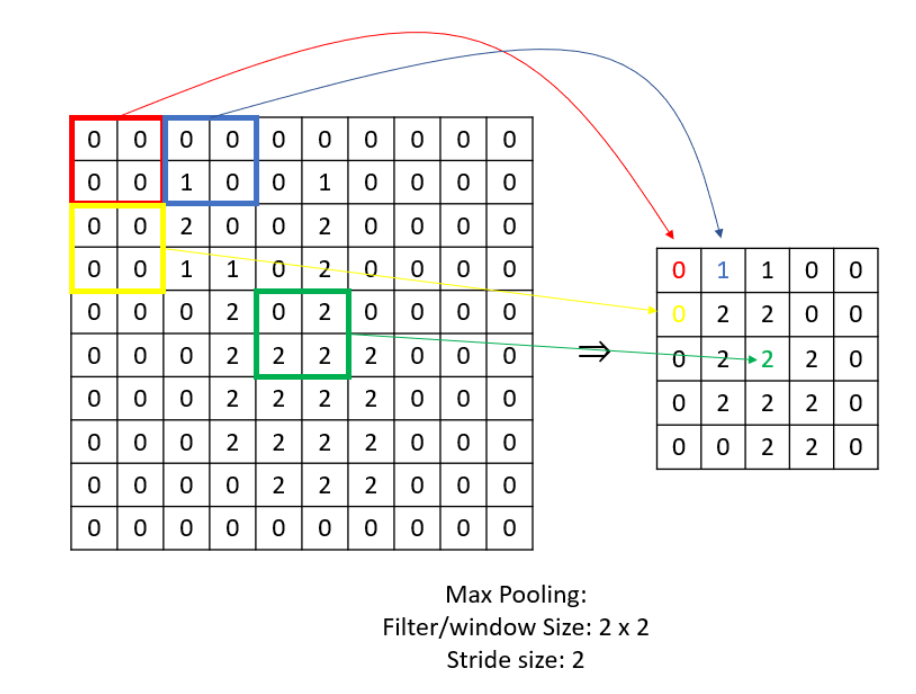
We will do this via a max pooling function. This function slides a window across the array taking the maximum value in that window and was previously applied to help Logistic Regression overcome memory issues when the size of the images were too large:

There are 2 important parameters of a max pooling function: Stride Size (s) and the window/filter size (f). If this is applied to an 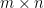






We will take the greatest multiple of of 127 that goes into 256. Remainder will then be 
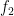
# get the dimensions of the images
m,n_h,n_w = ls_X.shape
# remainders
f1 = n_h % 127
f2 = n_w % 127
# quotients
s1 = int((n_h-f1)/127)
s2 = int((n_w-f2)/127)
print('The size of the images before transformation is:{} X {}'.format(n_h,n_w))
print('The dimensions of the window will be:f1 X f2 = {} X {} \nThe stride parameters will be: s1={} and s2={}'.format(f1,f2,s1,s2))
print('The size after transformation will be:{} X {}'.format(int((n_h - f1)/s1 + 1),int((n_w - f2)/s2 + 1)))
The size of the images before transformation is:256 X 256 The dimensions of the window will be:f1 X f2 = 2 X 2 The stride parameters will be: s1=2 and s2=2 The size after transformation will be:128 X 128
The following function applies this max pool transformation:
def transform_hands(ls_X,f1,f2,s1,s2,pooltype='avg'):
# for train
m,n_h,n_w = ls_X.shape[:3]
# declare x as a tensorflow constant
x = tf.constant(ls_X)
# reshape the tensor to have 4 dimensions. The last dimension is called the 'channel' and is usually 3, for RGB values of each pixel
x = tf.reshape(x, [m,n_h,n_w, 1])
# this is our max pooling function we obtain as an object from keras
if pooltype == 'avg':
max_pool_2d = tf.keras.layers.AveragePooling2D(pool_size=(f1, f2),strides=(s1, s2), padding='valid',dtype='float64')
else:
max_pool_2d = tf.keras.layers.MaxPooling2D(pool_size=(f1, f2),strides=(s1, s2), padding='valid',dtype='float64')
# apply the transformation
x = max_pool_2d(x)
# convert it back to numpy
nparray = x.numpy()
m,n_h_new,n_w_new = nparray.shape[:3]
ls_X_transformed = nparray.copy()
# reshape it back to how it was for the viewing in imshow
ls_X_transformed_temp = nparray.reshape((m,n_h_new,n_w_new,1))
print('Transformed from {} to {}'.format((m,n_h,n_w),ls_X_transformed_temp.shape))
return ls_X_transformed,ls_X_transformed_temp
We apply the max pool transformation
ls_X_transformed,ls_X_transformed_temp = transform_hands(ls_X,f1,f2,s1,s2,pooltype='max')
Transformed from (7, 256, 256) to (7, 128, 128, 1)
We can see below what the transformation actually did. We end up with a 128 X 128 image which tries to keep the features from the original large image.
print('Before max pooling')
plt.imshow(ls_X[0].reshape(ls_X[0].shape[0:2]))
plt.show()
print('After max pooling')
plt.imshow(ls_X_transformed_temp[0].reshape((ls_X_transformed_temp[0].shape[0],ls_X_transformed_temp[0].shape[1])))
plt.show()


Load the Model
Here, we load the models we had previously transformed.
# load the models
fingers_model = load_model(model_h5_save)
hand_model = load_model(model_h5_rlmodel_save)
Predict
We can then use these models to predict the number of fingers held up on my own hands as well as which hand I am using.
predictions = fingers_model.predict(ls_X_transformed)
predictions = tf.argmax(predictions, axis=1).numpy()
predictions
array([5, 4, 1, 3, 2, 2, 0], dtype=int64)
predictions = hand_model.predict(ls_X_transformed)
np.where(predictions >= 0.5,'L','R')
array([['R'],
['R'],
['R'],
['R'],
['R'],
['L'],
['L']], dtype='<U1')
The above shows that the model thinks I’m holding up a ‘5’, ‘4’, ‘1’, ‘3’ and ‘2’ on my right hand and a ‘2’ and ‘0’ on my left hand. We see below that this is indeed true:
for i in range(len(ls_X)):
plt.imshow(ls_X_transformed[i].reshape((128,128)))
plt.show()







Note
The above images were tailored to look similar to the train/test set used to develop the models. This is unrealistic. In reality we may not have images where the hand is nicely in the center of the image. Also, the background may not be black. Below, we try out a few other images highlighting this. The first image is a right-hand four and is different from the train/test set in the sense that you can see my wrist. The second image is a left-hand three and is different because the background is white/cream and the hand does not appear in the middle of the image. The third image is a right-hand two. This image is different because not only can you see my wrist, the hand doesn’t appear in the middle of the image.
# get a list of all the images that are in the directories
dir_all_images = os.listdir(dir_image_folder2)
# get the number of train/test examples
number_of_images = len(dir_all_images)
print('Number of images:',number_of_images)
Number of images: 3
for img_name in dir_all_images:
data = image.imread(os.path.join(dir_image_folder2,img_name))
plt.imshow(np.array(data))
plt.show()



# lists to store the images
ls_X = []
for img_name in dir_all_images:
data = image.imread(os.path.join(dir_image_folder,img_name))
ls_X.append(np.array(data))
ls_X = np.array(ls_X)
# convert to grayscale by averaging across rgb channel
ls_X = np.mean(ls_X,axis=3)
# scale by rgb values 255
ls_X = ls_X/255
print('Train images loaded:',len(ls_X))
Train images loaded: 3
ls_X_transformed,ls_X_transformed_temp = transform_hands(ls_X,f1,f2,s1,s2,pooltype='max')
Transformed from (3, 256, 256) to (3, 128, 128, 1)
predictions = fingers_model.predict(ls_X_transformed)
predictions = tf.argmax(predictions, axis=1).numpy()
predictions
array([4, 3, 2], dtype=int64)
predictions = hand_model.predict(ls_X_transformed)
np.where(predictions >= 0.5,'L','R')
array([['R'],
['R'],
['R']], dtype='<U1')
It turns out that the model doesn’t fair too badly. One important point is that the left-hand three is misclassified as being the right hand. Even though this is only a single misclassification, this is quite significant – remember that we obtained a 100% accuracy on the test set while developing the models.
There may be 2 reasons for this, depending on how you look at it:
- The test and train sets for model development was not representative of reality. We can try data augmentation as follows: duplicate the train/test data by changing the background colour or introducing some random fluctuations in the colours to allow the model to not overfit the image types given by the original train set. We could also try to shift the hand toward different locations in the images and change the sizes of the hands by padding black pixels to the edges and resizing. We could also go and get more realistic data (may be time consuming).
- We have overfit the training set. In others words, we have allowed the model to narrow down to the hand being in a particular location (middle) and a black background or the fingers to being quite thin. We were simply lucky that the test set was so similar to the training set. To combat this, we could try to introduce regularisation. One approach for regularisation in Neural Networks (apart from intruducing random fluctuations mentioned above which introduces some regularisation) is to apply Dropout. Dropout is a technique which randomly sets some neurons in a particular layer to have weight 0. This stops the network from relying too heavily on a subset of neurons.